

[ad_1]
2 บทเรียนที่ควรรู้
1. Gemma 2 2B เป็นโมเดลที่มีประสิทธิภาพดีที่สุดในขนาดเล็ก
โมเดล LLM Gemma 2 2B ถือเป็นโมเดลที่มีความสามารถที่เหนือกว่า GPT-3.5 ในขนาดใกล้เคียง นับว่าประสิทธิภาพดีที่สุดในขนาดใกล้เคียงกัน
2. Gemma 2 2B ประสิทธิภาพดีในการใช้งานใน Chatbot Arena
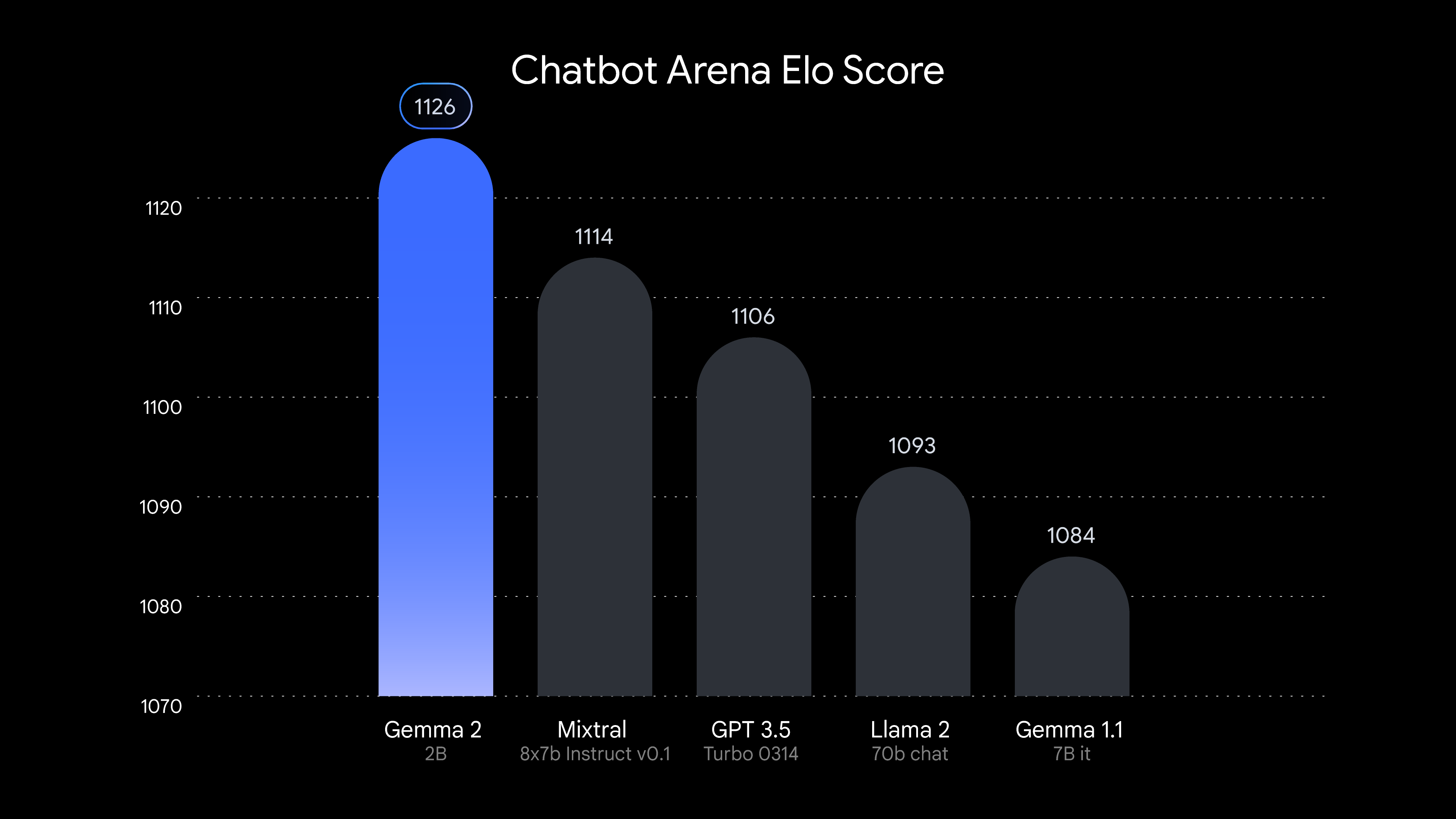
ผลทดสอบใน Chatbot Arena พบว่า Gemma 2 2B มีคะแนนดีเยี่ยมและเอาชนะได้ทั้ง GPT-3.5 หรือ ChatGPT ตัวแรก, Mixtral 8x7B ที่มีขนาดใหญ่, หรือ Llama 2 70B
2 ปัญหาและวิธีการแก้ไข
1. ปัญหาในความสัมพันธ์ระหว่างขนาดข้อมูลและผลทดสอบ
โมเดล Gemma 2 2B ฝึกด้วยข้อมูลขนาดเล็ก 2 ล้านล้านโทเค็น และผลทดสอบแสดงให้เห็นว่าผลตอบรับยังมีความแปรปรวนเมื่อเปรียบเทียบกับโมเดลขนาดใหญ่
2. ปัญหาในการสร้างโมเดลที่มีความ透เสียแต่ยังมีประสิทธิภาพ
การสร้างโมเดลที่ใช้ข้อมูลขนาดใหญ่แต่ยังคงมีความ透เสียเป็นปัญหาที่ต้องหาวิธีการแก้ไขให้เหมาะสม
3 คำถามที่ถามบ่อย
– Gemma 2 2B มีประสิทธิภาพในการทำงานที่ใดบ้าง?
– วิธีการฝึก Gemma 2 2B ใช้อะไรบ้าง?
– Gemma 2 2B มีความแตกต่างจาก GPT-3.5 อย่างไร?
5 เว็บไซต์ที่เกี่ยวข้อง
- Google for Developers – ที่มาของข้อมูล
- Blognone – บทความที่เกี่ยวข้องกับ Gemma 2 2B
- Facebook – เว็บไซต์ของ Facebook
- Connect.facebook.net – ลิงก์สำหรับเชื่อมต่อกับ Facebook
- Blognone.com – บทความอื่นๆ ที่เกี่ยวข้อง
5 คำค้นหาที่เกี่ยวข้อง
- LLM Gemma 2 2B
- GPT-3.5
- Chatbot Arena
- NVIDIA T4
- Google Colab
กูเกิลปล่อยโมเดล LLM Gemma 2 2B โมเดลขนาดเล็กเพื่อการรันบนอุปกรณ์โดยตรง ชูความสามารถที่เหนือกว่า GPT-3.5 นับว่าเป็นโมเดลที่ประสิทธิภาพดีที่สุดในขนาดใกล้เคียงกัน
โมเดลนี้ฝึกด้วยชุดข้อมูลขนาด 2 ล้านล้านโทเค็น ด้วยข้อมูลเว็บ, โค้ด, และข้อมูลคณิตศาสตร์ นับว่าชุดข้อมูลเล็กกว่าโมเดลขนาดใหญ่กว่ามาก ผลที่ได้คือคะแนนทดสอบ เช่น MMLU อยู่ที่ 51.3 ต่ำกว่าโมเดลขนาดใหญ่ค่อนข้างมาก หรือชุดทดสอบเขียนโค้ด HumanEval อยู่ที่ 17.7 เท่านั้น อย่างไรก็ดีผลทดสอบใน Chatbot Arena ที่ทดสอบด้วยผู้ใช้งานจริงนั้นกลับได้คะแนนดีมาก เอาชนะได้ทั้ง GPT-3.5 หรือ ChatGPT ตัวแรก, Mixtral 8x7B ที่มีขนาดใหญ่, หรือ Llama 2 70B
ด้วยโมเดลขนาดเล็กเท่านี้ ทำให้เราสามารถรันโมเดลที่ไหนก็ได้ รวมถึงการใช้งานบนชิป NVIDIA T4 ที่ Google Colab ให้บริการฟรี
นอกจาก Gemma 2 2B ตัวหลักแล้ว กูเกิลยังปล่อยโมเดล ShieldGemma สำหรับคัดกรองเนื้อหาอันตราย พร้อมกับ Gemma Scope เครื่องมือแสดงการทำงานภายในของ Gemma 2 ที่เปิดให้ส่องกระบวนการภายในได้ว่าโมเดลมองคำใดจึงสร้างคำตอบออกมา
ที่มา – Google for Developers

[ad_2]
Source link
https://www.blognone.com/node/141188