

[ad_1]
2 บทเรียน ที่ควรรู้
- การขยายขนาด context window สามารถเพิ่มประสิทธิภาพให้กับโมเดล AI: คำดัชนีของ Mistral Large 2 ที่มีการขยายขนาด context window จาก 32K เป็น 128K ทำให้โมเดลสามารถรองรับภาษาและภารกิจต่างๆ ได้มากขึ้น
- ความสำคัญของการเปรียบเทียบคะแนนทดสอบและประสิทธิภาพต่อต้นทุน: การเปรียบเทียบคะแนนทดสอบระหว่าง Mistral Large 2 กับโมเดลคู่แข่งสำคัญในการตัดสินใจเลือกใช้โมเดลที่เหมาะสมที่สุดตามความต้องการ
2 ปัญหา และ วิธีการแก้ไข
- ความรุนแรงของโมเดล AI ในการเขียนโปรแกรมและตอบคำถามคณิตศาสตร์: ความรุนแรงของโมเดล Mistral Large 2 สามารถทำให้โมเดลเกินกำลังในบางกรณี การเฝ้าดูแลและปรับค่าพารามิเตอร์อย่างเหมาะสมจึงเป็นวิธีการแก้ไข
- ความจำเป็นในการซื้อไลเซนส์จาก Mistral หรือผู้ให้บริการคลาวด์พันธมิตร: การเปิดใช้งานโมเดล Mistral Large 2 ต้องซื้อไลเซนส์จากผู้ให้บริการที่มีสัญญากับ Mistral เป็นปัญหา สามารถหาข้อตกลงหรือวิธีที่ทำให้การใช้งานเป็นไปอย่างมีประสิทธิภาพ
3 คำถามที่ถามบ่อย
- โมเดล AI ที่มีขนาดพารามิเตอร์มาก มีประสิทธิภาพมากขนาดเท่าไหร่?: ความสัมพันธ์ระหว่างขนาดพารามิเตอร์และประสิทธิภาพของโมเดล AI
- การขยายขนาด context window ส่งผลต่อประสิทธิภาพของโมเดล AI อย่างไร?: วิธีที่การขยายขนาด context window สามารถช่วยให้โมเดลได้ประสิทธิภาพมากขึ้น
- วิธีการเปรียบเทียบคะแนนทดสอบระหว่างโมเดล AI หลายรุ่น: วิธีการเปรียบเทียบคะแนนทดสอบและประสิทธิภาพของโมเดล AI ในสถานการณ์แตกต่าง
5 เว็บไซต์ที่เกี่ยวข้อง
- Blognone – Mistral NeMo 12B
- Blognone – Mistral Large 1
- Blognone – Meta Llama 3.1 405B
- Mistral AI – Mistral
5 คำค้นหาที่เกี่ยวข้อง
- โมเดล Mistral Large 2
- คะแนนทดสอบโมเดล AI
- ประสิทธิภาพต่อต้นทุนของโมเดล AI
- การเปรียบเทียบโมเดล AI
- การใช้งานโมเดล AI ในเชิงวิจัย
คล้อยหลังการเปิดตัวโมเดล Mistral NeMo 12B รุ่นเล็กเพียงไม่กี่วัน ทาง Mistral AI ก็เปิดตัวโมเดลขนาดใหญ่ระดับเรือธง Mistral Large 2 ขนาดพารามิเตอร์ 123B เป็นเวอร์ชันอัพเกรดของ Mistral Large 1 ที่ออกเมื่อต้นปี 2024
สิ่งที่เพิ่มเข้ามาคือการขยายขนาด context window จาก 32K เป็น 128K, รองรับภาษาอื่นๆ ที่ไม่ใช่ภาษาตระกูลละติน ได้แก่ อารบิก ฮินดี จีน ญี่ปุ่น เกาหลี, รองรับภาษาโปรแกรมมิ่งอีกกว่า 80 ภาษา
ในแง่คะแนนการทดสอบ Mistral Large 2 ทำคะแนนชุดทดสอบ MMLU ได้ 84%, ส่วนคะแนนการเขียนโปรแกรมและตอบคำถามคณิตศาสตร์ บอกว่าอยู่ระดับเดียวกับ GPT-4o, Claude 3 Opus และ Llama 3 405B
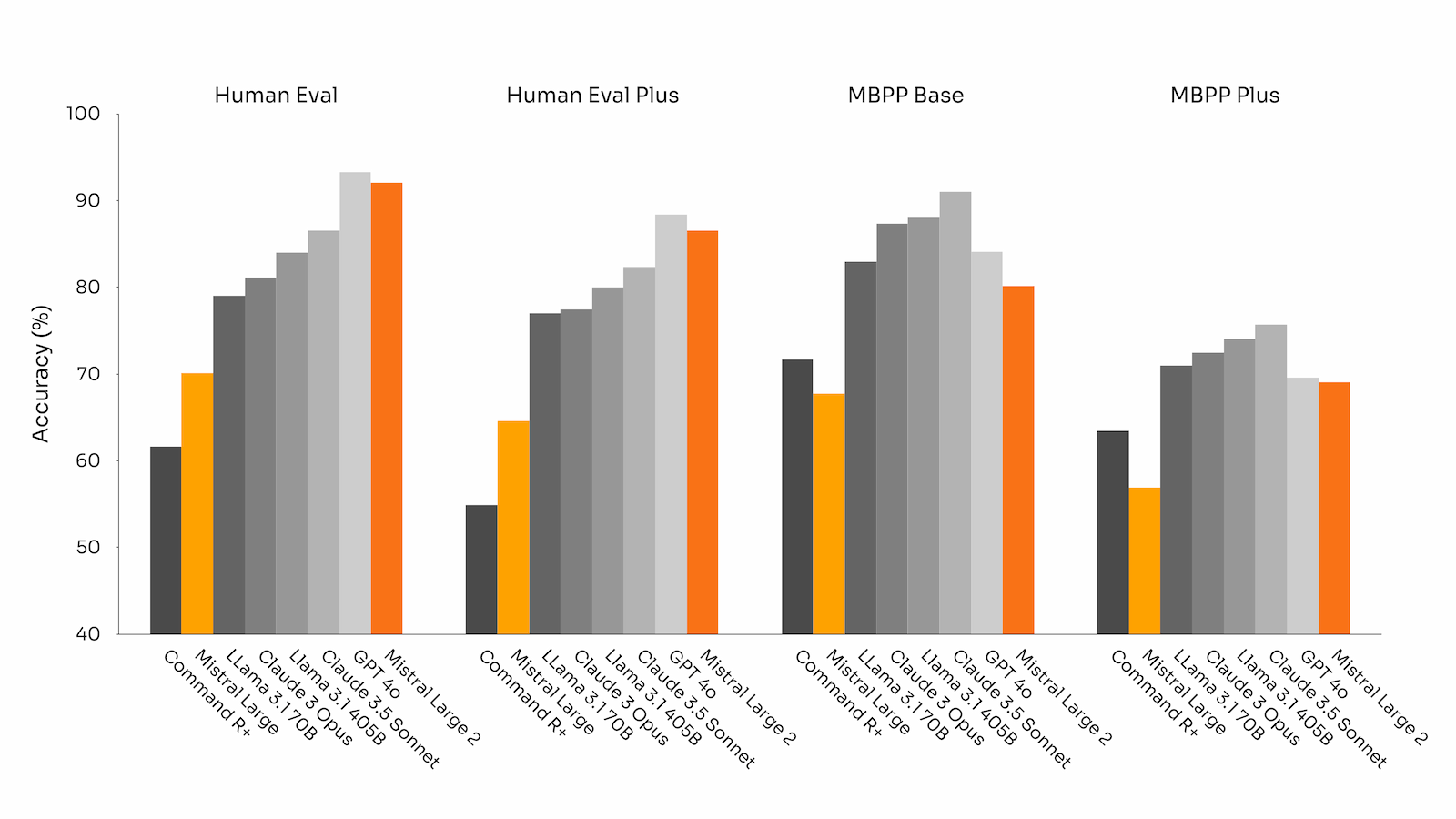
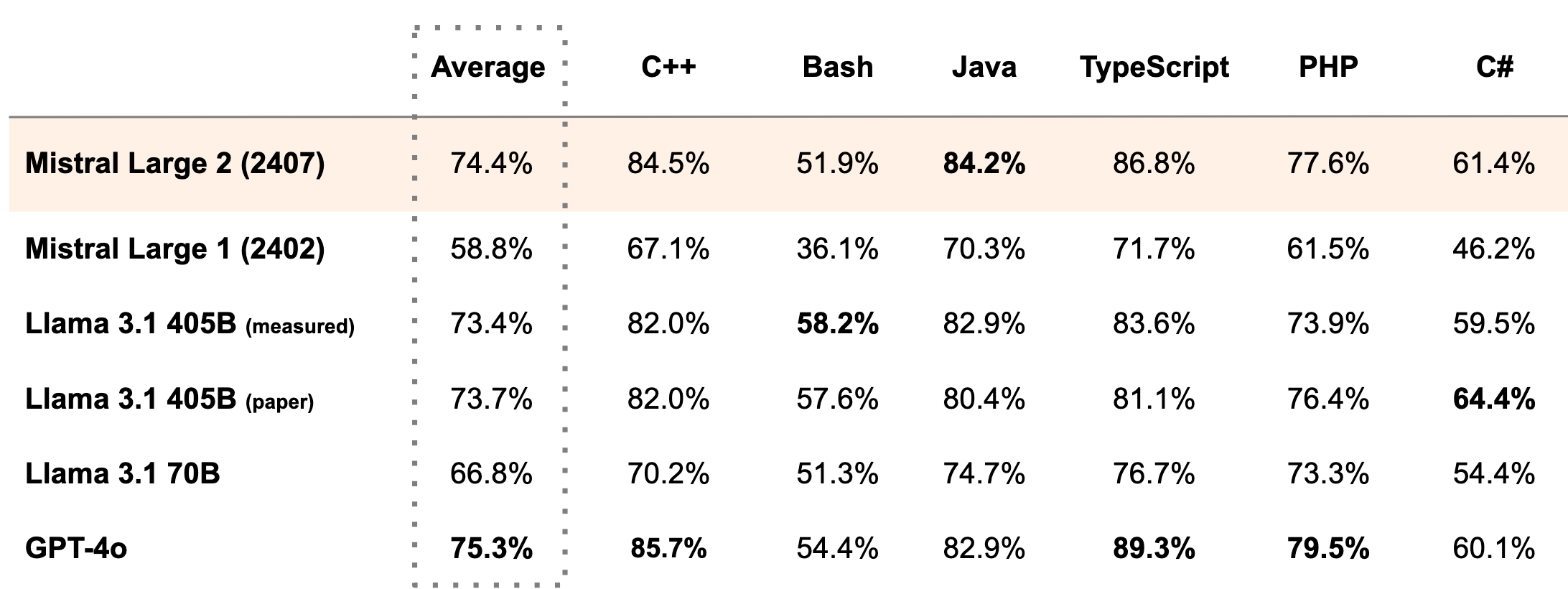
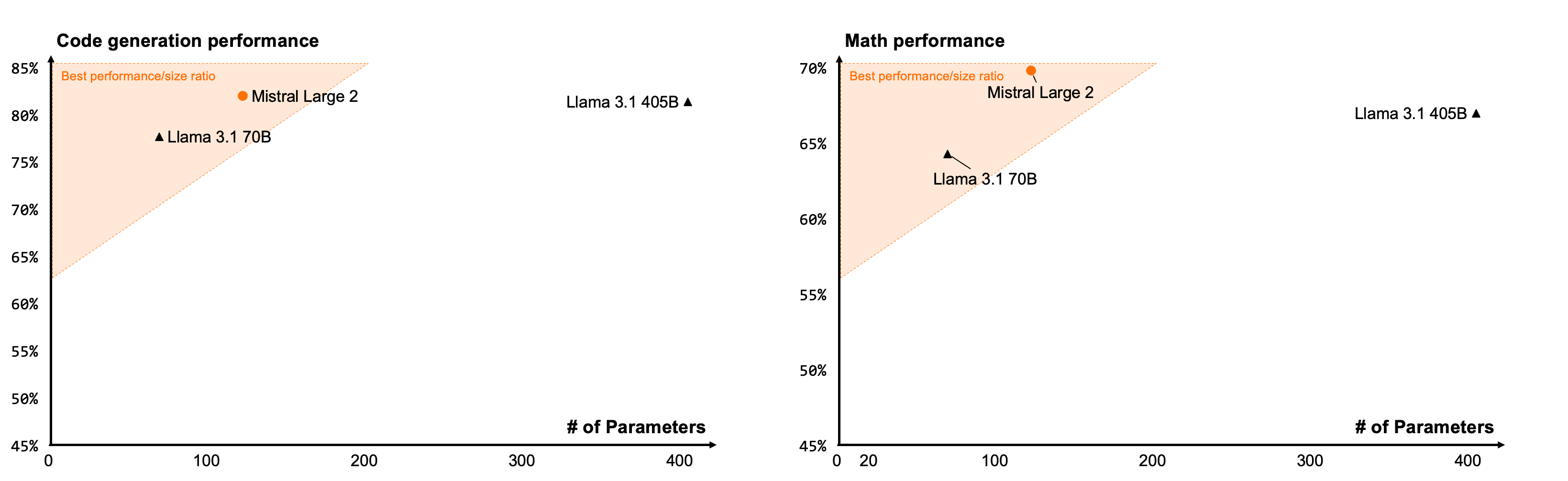
Mistral Large 2 ออกแบบมาให้รันในเครื่องเดียว (single-node inference) โดยมีขนาดพารามิเตอร์ 123B ไม่จำเป็นต้องหาเครื่องเพิ่ม จึงมีจุดเด่นเรื่องประสิทธิภาพต่อต้นทุน (นับตามจำนวนพารามิเตอร์) ที่เหนือกว่าโมเดลภาษาคู่แข่งอื่นๆ โดยเฉพาะ Meta Llama 3.1 405B ที่เพิ่งออกมาเมื่อวาน เพราะ Mistral Large 2 มีคะแนนทดสอบน้อยกว่าเล็กน้อย แต่พารามิเตอร์น้อยกว่าประมาณ 3 เท่า
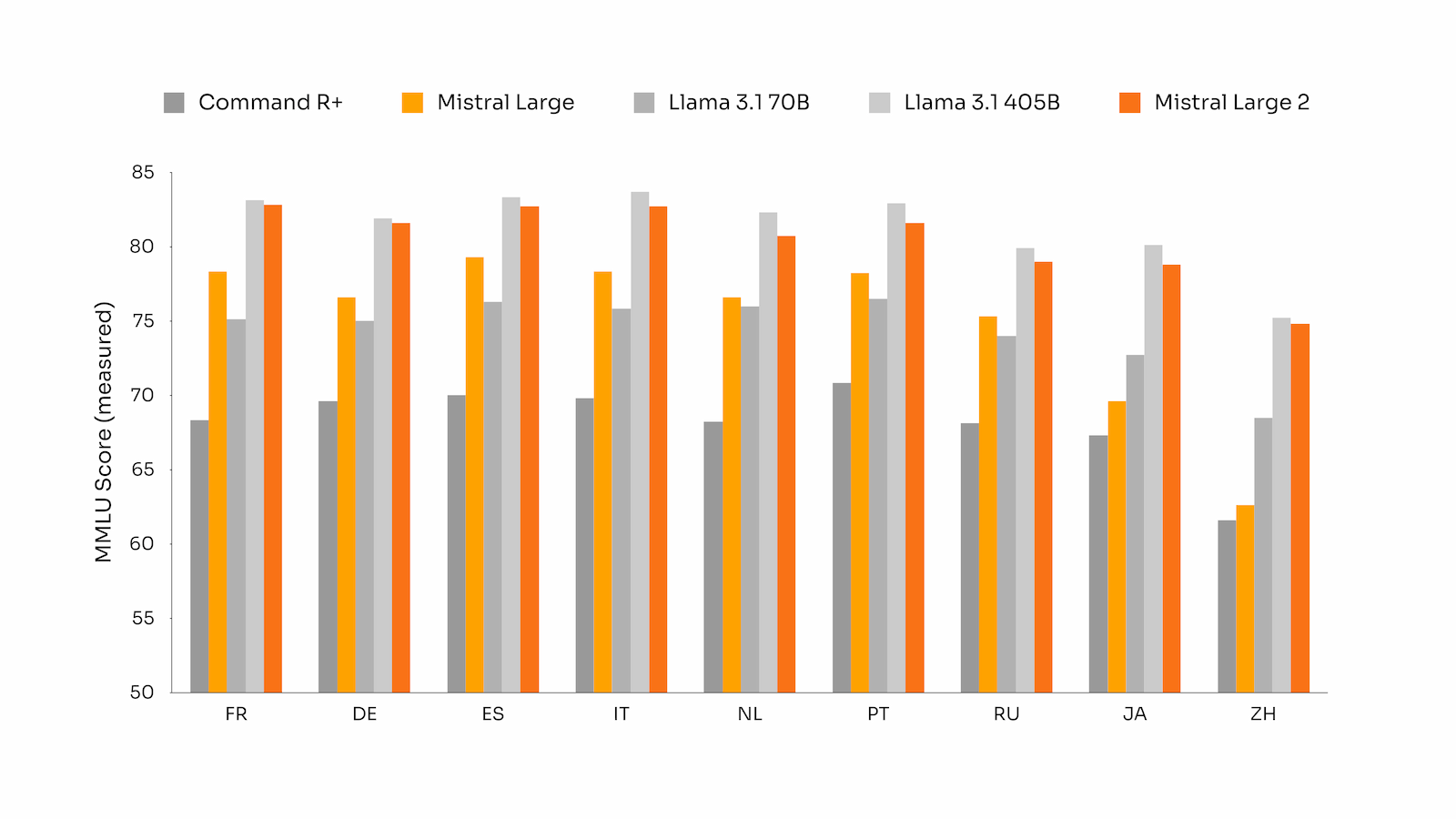
อย่างไรก็ตาม Mistral Large 2 ไม่เปิดให้ใช้งานฟรีในเชิงพาณิชย์ ต้องซื้อไลเซนส์จาก Mistral หรือผู้ให้บริการคลาวด์พันธมิตร แต่ถ้าเป็นการใช้ในเชิงวิจัยหรืองานที่ไม่ใช่การพาณิชย์ก็สามารถใช้งานได้ ตรงนี้ยังเป็นจุดที่ Llama 3 ได้เปรียบกว่า
ที่มา – Mistral
[ad_2]
Source link
https://www.blognone.com/node/141079